Access, quota, and usage support for AI coding tools across command line, plugins, desktop apps, and multi-agent workflows.
Build with vision, ship with your agent.
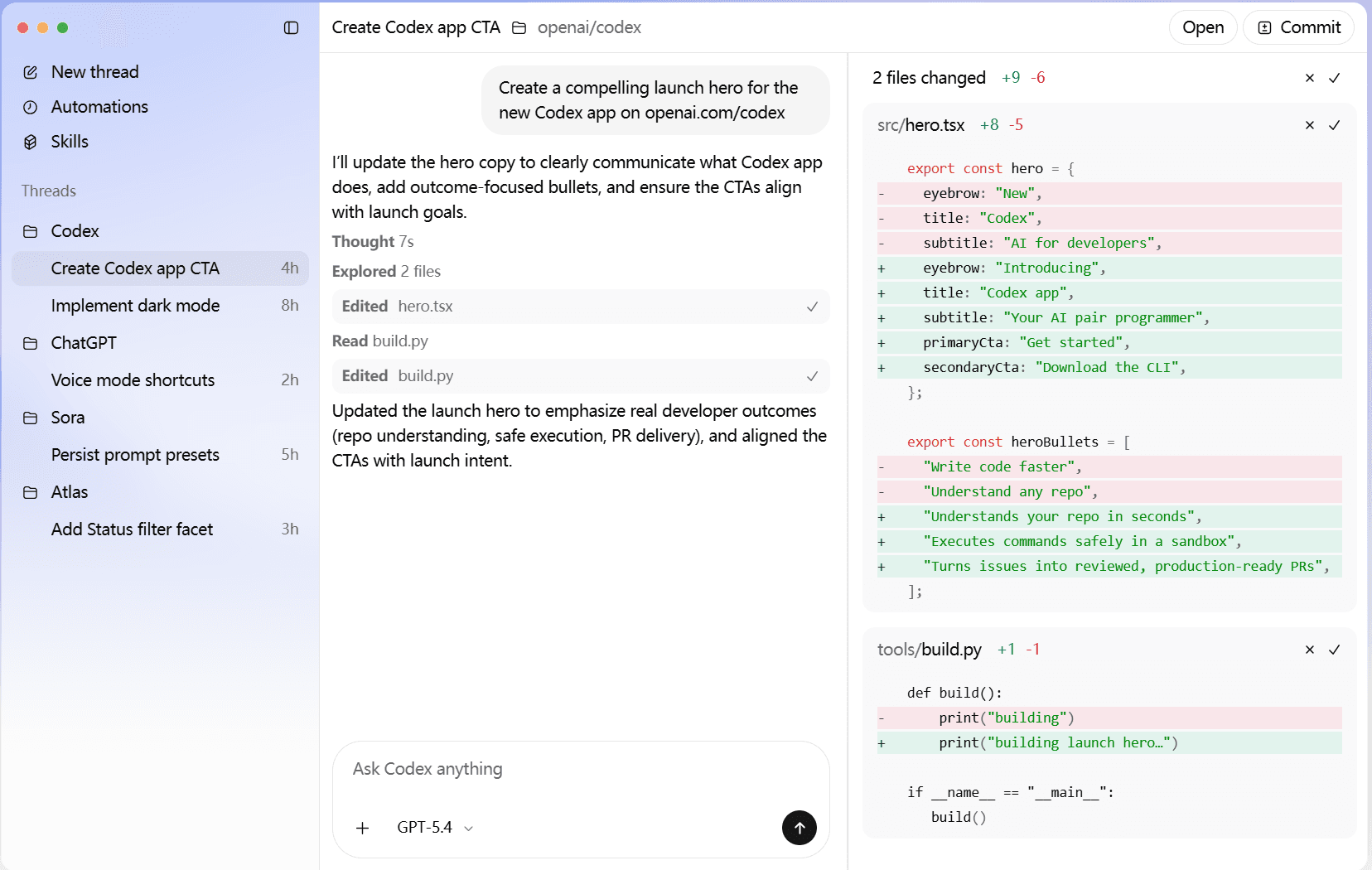
This UI demo illustrates Codex CLI's core workflow only. For the complete feature set, please refer to the official Codex CLI release. 4096Bytes provides production-grade access for native CLI and multi-surface development environments.
Break tool boundaries. Build your own AI collaboration workspace with one API key.
Carry forward the CLI's hardcore DNA, unlock AI potential through the Harness architecture, and adapt it to multi-surface collaboration. From terminal to desktop, Codex stays alongside your code.
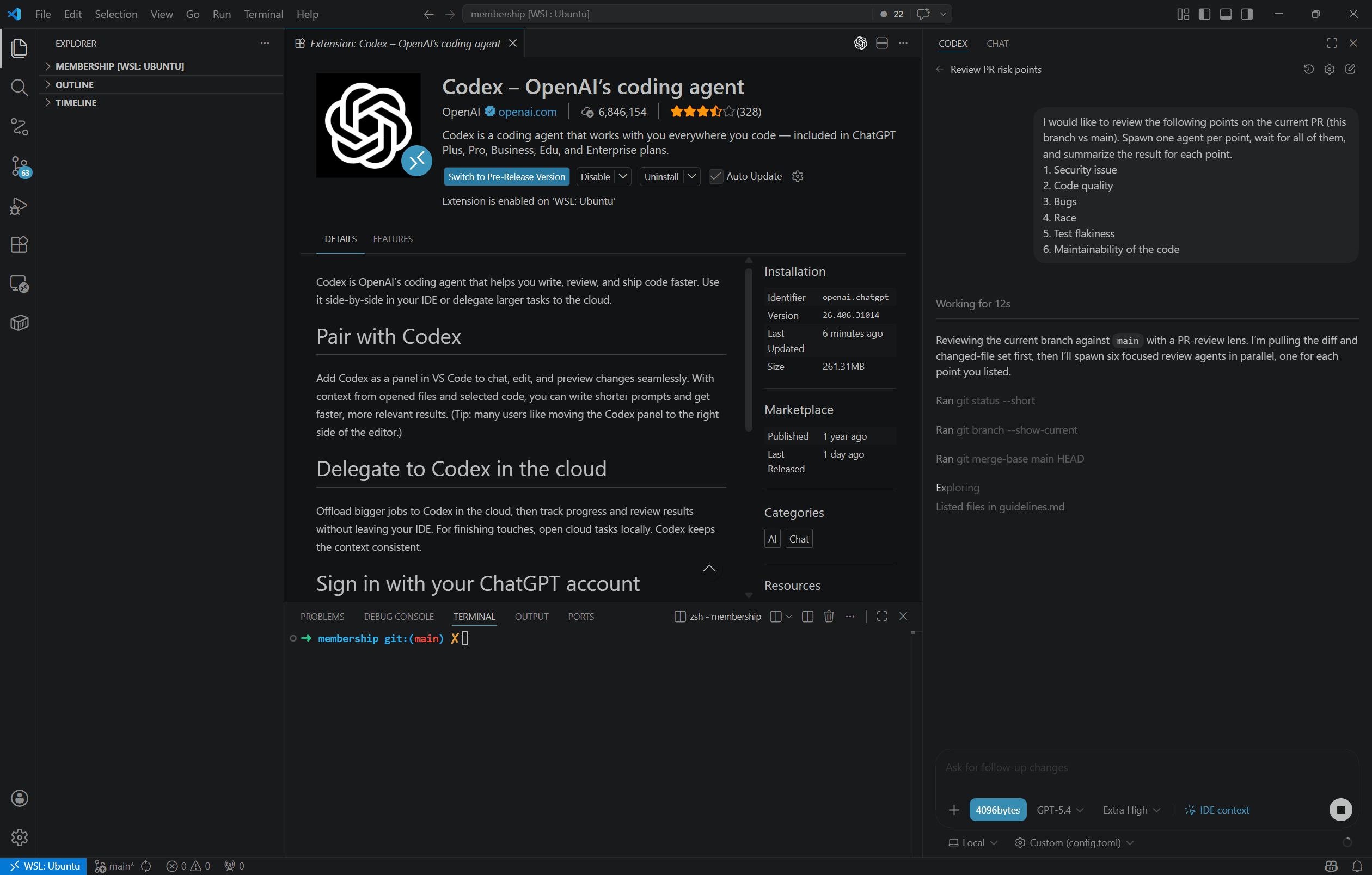
Why 4096Bytes
Built for daily AI coding workflows with faster throughput, stable routing, caching gains, and transparent spend visibility.
THROUGHPUT
500k+
Tokens per minute
Burst-ready queues
CONTEXT CACHING
Up to 90%
Lower latency and cost
Warm prompt reuse
SMART ROUTING
99.9%
Uptime SLA
Fallback path active
TRANSPARENCY
Real-time
USD Billing/Metrics
Live spend meter
Pricing for every stage of development
Start with PAYGO, move to Pro, or talk to us for Enterprise Custom.
PAYGO
¥19.90 / day
Core quota · $100 USD daily quota
- Best for Urgent access / evaluation
- Top-tier response priority
- Direct mainland access, no VPN needed
Pro
¥368 / month
Core quota · $200 USD daily quota
- Best for Deep development / long-running projects
- Includes everything in PAYGO
- High concurrency for agent fleets
- Lower effective daily cost than daily passes
- Built for all-day heavy development
Enterprise Custom
Contact sales
Core quota · Dedicated high-volume quota
- Best for Large-scale deployment / dedicated cluster
- Dedicated compute cluster deployment
- SLA and white-glove support
Model Cost Conversion
Token prices are shown per 1M tokens so you can translate GPT and Codex usage into real dollar cost at a glance.
All figures below are priced per 1M tokens.
MODEL NAME
INPUT (1M)
OUTPUT (1M)
CACHE DISCOUNT
GPT-5.4LATEST
INPUT (1M)$2.50
OUTPUT (1M)$15.00
CACHE DISCOUNT-90%
GPT-5.3-Codex
INPUT (1M)$1.75
OUTPUT (1M)$14.00
CACHE DISCOUNT-90%
GPT-5.2-Codex
INPUT (1M)$1.75
OUTPUT (1M)$14.00
CACHE DISCOUNT-90%
GPT-5.1-Codex-Max
INPUT (1M)$1.25
OUTPUT (1M)$10.00
CACHE DISCOUNT-90%
GPT-5.2
INPUT (1M)$1.75
OUTPUT (1M)$14.00
CACHE DISCOUNT-90%
GPT-5.1-Codex-mini
INPUT (1M)$0.25
OUTPUT (1M)$2.00
CACHE DISCOUNT-90%
GPT-5.3-Codex-SparkPREVIEW
INPUT (1M)TBD
OUTPUT (1M)TBD
CACHE DISCOUNTTBD
* GPT-5.3-Codex-Spark is currently a research preview in Codex. OpenAI has not published final token pricing for it yet.
Frequently asked questions
Everything developers usually ask before moving daily Codex workflows onto a managed access layer.
FAQ Topic
Network & Access
No. We optimize the relay path for direct mainland access, so Codex feels native inside VS Code or your IDE without obvious latency.